

ha wget wget.... quand tu nous aspires!
Précédement, nous avons procédé à l'aspiration des pages web, à l'aide de la commande "curl". Cependant cette dernière ne peut traiter les urls que de maniére individuelle. La commande wget quant à elle est beaucoup plus puissante puisqu'elle permet une aspiration récursive (peut aspirer un site entier!!!!!). Etant toujours à la recherche d'un traitement le plus optimal et le plus économique possible, nous nous sommes dit qu'il serait interessant ( voir judicieux!) d'utiliser la commande wget pour effectuer l'aspiration de nos pages.
A l'interieur de notre script nous avons egalement mis en oeuvre un traitement qui ne garde pas toutes les balises html dans nos pages aspirées, mais uniquement le contenu textuel. Pour cela on a utilisé la commande "lynx" (qui permet de dumper, filtrer le texte.) avec les otions -dump -nolist -display_charset qui permettent respectivement de transformer en texte le contenu html (-dump) de supprimer les listes (-nolist) et d'afficher la page dans l'encodage choisi (- display_charset).
Avant de lancer le dump, nous avons verifié que les pages été encodé en utf-8, si ce n'etait pas le cas, on a cherché à connaitre l'encodage de la page grace à la commande "file -i". Quand l'encodage est connu on le converti en utf-8 à l'aide de la commande i conv. Puis on lance le "dump" En revanche quand le charset est inconnu on ne fait rien.
Voici le script utilisé:


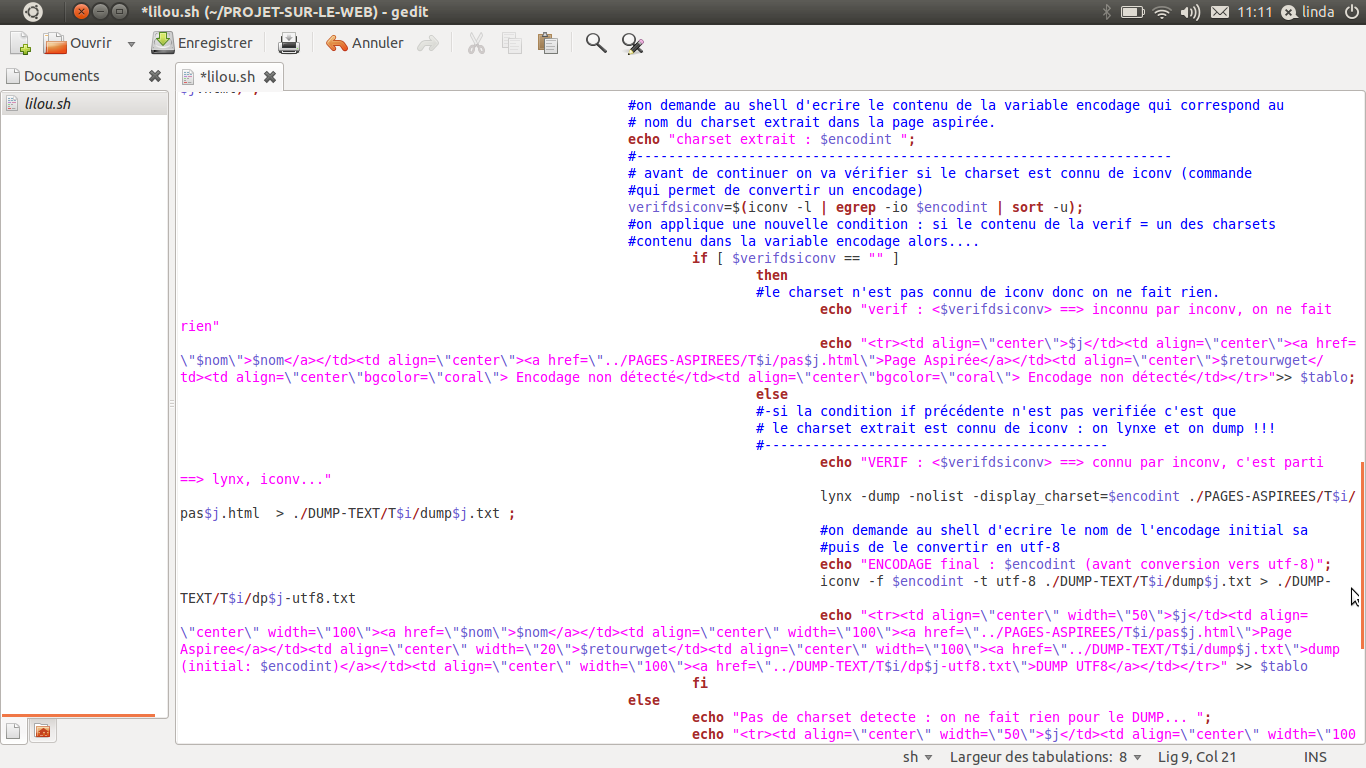

Et voilà le résultat (enfin une partie du tableau 1 et 2) une fois le script lancé dans le shell:


Petite analyse du résultat:
On remarquera que pour les urls en portugais le traitement est un franc succés: Toutes les urls à l'exeption de seulement deux petites rebelles ont été aspiré. L'encodage (initial ou vonverti) est bien en sotie en utf-8.
Hélas, on ne peut pas en dire autant pour les urls en français puisque la pluspart n'ont pas été aspiré. Les sites étant protégés (accés interdit) le dump n'a pu être effectué. Il va donc falloir se remettre à la recherche de nouvelles urls pour la suite.
Autre petit problème: Quand on regarde le retour du wget, on s'apperçoit qu'il nous indique uniquement le code erreur 0 (ok) ou 8 (?), mais pas le contenu de la page aspirée (obtenu en utilisant la commande egrep) lorsque l'accés à la page est interdit (bad request, accés interdit...). Nous n'avons pas encore trouver la causes ni la solution à ce tout petit probléme.
A suivre...
Lintia